
As software names go, Google’s “Parsey McParseface” isn’t a very serious one. But Parsey McParseface carries out a very serious function: parsing out the English language. “Parsey McParseface is built on powerful machine learning algorithms that learn to analyze the linguistic structure of language,” read a recent posting on Google’s Research Blog, “and that can explain the functional role of each word in a given sentence.” Google claims that Parsey McParseface is the “most accurate such model in the world,” at least based on a recent paper dissecting globally normalized transition-based neural networks. Parsey McParseface is part of Google’s new SyntaxNet, an open-source neural network framework implemented in the open-source TensorFlow machine-learning system. SyntaxNet can resolve the ambiguities of phrasing by weighing and scoring the dependencies between words: 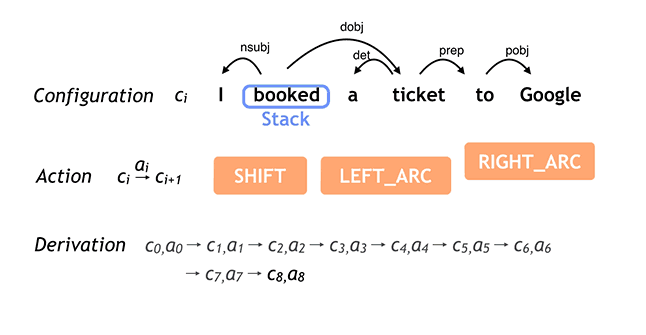 Why is any of that important to you? Because computers have a hard time understanding (and processing) human language; if they get better at it, we’ll see more effective “digital assistants” and bots. When it comes to English (and Parsey McParseface), Google used randomly drawn newswire sentences as a benchmark. The software accurately parsed sentences 94 percent of the time. “While there are no explicit studies in the literature about human performance,” the blog added, “we know from our in-house annotation projects that linguists trained for this task agree in 96-97 [percent] of cases.” In tests performed with random sentences from the Web, Parsey McParseface performed slightly worse, at 90 percent accuracy. But if Google keeps refining SyntaxNet, chances are good that percentage will only improve in coming years. And where does the name “Parsey McParseface” come from? It seems to be a play on “Boaty McBoatface,” a crowdsourced name for a polar research vessel. Isn’t language a beautiful thing?
Why is any of that important to you? Because computers have a hard time understanding (and processing) human language; if they get better at it, we’ll see more effective “digital assistants” and bots. When it comes to English (and Parsey McParseface), Google used randomly drawn newswire sentences as a benchmark. The software accurately parsed sentences 94 percent of the time. “While there are no explicit studies in the literature about human performance,” the blog added, “we know from our in-house annotation projects that linguists trained for this task agree in 96-97 [percent] of cases.” In tests performed with random sentences from the Web, Parsey McParseface performed slightly worse, at 90 percent accuracy. But if Google keeps refining SyntaxNet, chances are good that percentage will only improve in coming years. And where does the name “Parsey McParseface” come from? It seems to be a play on “Boaty McBoatface,” a crowdsourced name for a polar research vessel. Isn’t language a beautiful thing?


